A new Apple patent (number20120265533) at the U.S. Patent & Trademark Office for “voice assignment for text-to-speech output” shows that Apple is looking to add more variety and flavor to text-to-speech voices.
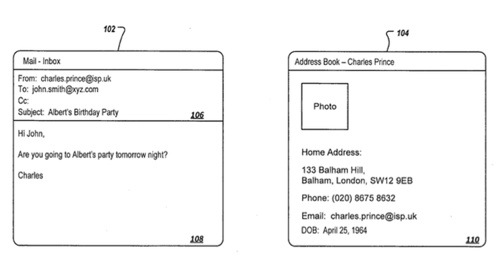
Per the patent, text can be obtained at a device from various forms of communication such as e-mails or text messages. Metadata can be obtained directly from the communication or from a secondary source identified by the directly obtained metadata.
The metadata can be used to create a speaker profile. The speaker profile can be used to select voice data. The selected voice data can be used by a text-to-speech (TTS) engine to produce speech output having voice characteristics that best match the speaker profile.
Here’s Apple’s background and summary of the invention: “Many modern computing devices (e.g., personal computers, smart phones, electronic tablets, television systems) run applications that convert text to speech. This conversion allows a user to listen to messages received in text format through email, texting or other communication technology.
“Such applications are especially useful to vision impaired users. Text-to-speech engines often generate synthesized speech having voice characteristics of either a male speaker or a female speaker. Regardless of the gender of the speaker, the same voice is used for all text-to-speech conversion regardless of the source of the text being converted.
“Text can be obtained at a device from various forms of communication such as e-mails or text messages. Metadata can be obtained directly from the communication or from a secondary source identified by the directly obtained metadata. The metadata can be used to create a speaker profile. The speaker profile can be used to select voice data. The selected voice data can be used by a text-to-speech (TTS) engine to produce speech output having voice characteristics that best match the speaker profile.
“Particular implementations of voice assignment for synthesized speech, provides one or more of the following advantages. Text can be converted to speech using a voice that best matches a speaker profile that includes gender, age, dialect or any other metadata that defines voice characteristics of the speaker. Providing a speech output that is associated with a speaker profile allows speaker recognition while providing a more enjoyable and entertaining experience for the listener.”
Jonathan David Honeycutt is the the inventor.
Also appearing today at the U.S. Patent & Trademark Office are:
° Patent number 20120263019 for techniques and devices for utilizing passively received audio signals to determine proximity of devices to other objects.
° Patent number 20120265921 for systems and methods for storing and retrieving boot data (e.g., a first stage bootloader) in and from a non-volatile memory (“NVM”), such as a NAND flash memory.
° Patent number 20120264460 for location determination using a formula;
° Patent number 20120262475 for a method and apparatus to increase bit-depth on gray-scale and multi-channel images (inverse dithering);
° Patent number 20120265922 for systems and methods are disclosed for stochastic block allocation for improved wear leveling for a system having non-volatile memory (“NVM”).
° Patent number 20120265795 for systems, methods, and non-transitory computer-readable storage media for generating random data at an early stage in a boot process.
° Patent number 2012026242 for methods and apparatuses are disclosed for improving switching between graphics processing units (GPUs).
° Patent number 20120262379 for a system that facilitates interaction between an electronic device and a remote display.
° Patent number 20120262599 for dynamic exposure metering based on face detection;
° Patent number 20120266061 for procedurally expressing graphic objects for web pages.


