An Apple patent (number 7,765,213) for an ordered index has appeared at the US Patent & Trademark Office. The company is examining ways to make the retrieval of information easier and more efficient on Mac OS X.
Systems and methods for processing an index are described. A postings list of items containing a particular term are ordered in a desired retrieval order, e.g., most recent first. The ordered items are inserted into an inverted index in the desired retrieval order, resulting in an ordered inverted index from which items may be efficiently retrieved in the desired retrieval order. During retrieval, items may first be retrieved from a live index, and the retrieved items from the live and ordered indexes may be merged. The retrieved items may also be filtered in accordance with the items’ file grouping parameters. The inventors are Wayne Loofbourrow, John Martin Hoernkvist, Eric Richard Koebler and Yan Arrouye.
Here’s Apple’s background and summary of the invention: “Modern data processing systems, such as general purpose computer systems, allow the users of such systems to create a variety of different types of data files. For example, a typical user of a data processing system may create text files with a word processing program such as Microsoft Word or may create an image file with an image processing program such as Adobe’s PhotoShop. Numerous other types of files are capable of being created or modified, edited, and otherwise used by one or more users for a typical data processing system. The large number of the different types of files that can be created or modified can present a challenge to a typical user who is seeking to find a particular file which has been created.
Modern data processing systems often include a file management system which allows a user to place files in various directories or subdirectories (e.g. folders) and allows a user to give the file a name. Further, these file management systems often allow a user to find a file by searching not only the content of a file, but also by searching for the file’s name, or the date of creation, or the date of modification, or the type of file. An example of such a file management system is the Finder program which operates on Macintosh computers from Apple Computer, Inc. of Cupertino, Calif. Another example of a file management system program is the Windows Explorer program which operates on the Windows operating system from Microsoft Corporation of Redmond, Wash.
“Both the Finder program and the Windows Explorer program include a find command which allows a user to search for files by various criteria including a file name or a date of creation or a date of modification or the type of file. This search capability searches through information which is the same for each file, regardless of the type of file. Thus, for example, the searchable data for a Microsoft Word file is the same as the searchable data for an Adobe PhotoShop file, and this data typically includes the file name, the type of file, the date of creation, the date of last modification, the size of the file and certain other parameters which may be maintained for the file by the file management system.
“Certain presently existing application programs allow a user to maintain data about a particular file. This data about a particular file may be considered metadata because it is data about other data. This metadata for a particular file may include information about the author of a file, a summary of the document, and various other types of information. Some file management systems, such as the Finder program, allow users to find a file by searching through the metadata.
“In a typical system, the various content, file, and metadata are indexed for later retrieval using a program such as the Finder program, in what is commonly referred to as an inverted index. For example, an inverted index might contain a list of references to documents in which a particular word appears. Given the large numbers of words and documents in which the words may appear, an inverted index can be extremely large. The size of an index presents many challenges in processing and storing the index, such as updating the index or using the index to perform a search.
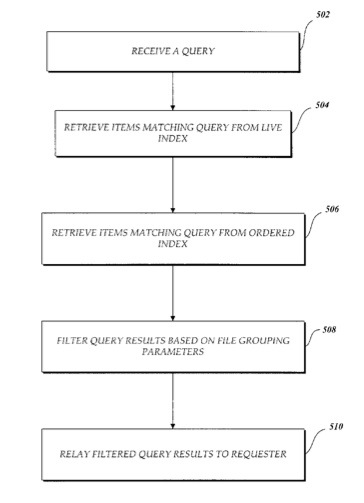
“Methods and systems for processing an inverted index in a data processing system are described herein. According to one aspect of the invention, a method for preparing an ordered inverted index is described that, among other advantages, allows for faster retrieval of items from the index. While scanning items to index the terms that the items contain, a postings list of items containing a particular term are ordered in a desired retrieval order. The ordered items are inserted from the postings list into an index in the in the desired retrieval order to create an ordered inverted index. During retrieval, items from the ordered inverted index are returned in the desired retrieval order more quickly and efficiently than if they were retrieved from a conventional unordered index.
“According to one aspect of the invention, additional efficiency in retrieving items in the desired retrieval order may be realized by generating a second inverted index separate from the ordered inverted index, where the second inverted index is generated from live items, i.e., recently created or updated items that represent current, or ‘live,’ updates to the ordered inverted index. During retrieval, the live items are retrieved from the second inverted index and returned first to insure that the live items are returned before other items from the ordered inverted index.
According to one aspect of the invention, further efficiency in retrieval of items from an inverted index may be achieved by storing the indexed items’ file grouping parameters separately, outside the inverted index. During later retrieval, an item’s file grouping parameters can be read very quickly, and only query results for selected groups need be evaluated further.”